Below some of the approaches, ideas and tools used.
enjoy.
Why am I talking about this, now?
Because exploring creative ways to use new technologies is my job :)

teaching machines & machines learning

The AI space as a pixel soup to hunter-gather your design building blocks, with intent

The design workflow is already filled by AI tools and processes

GPU ❤️🔥 +
DATA (extractivism) ⛏️ = new AI models

⏳ research -> concept -> application

micro-Apps for every workflow

new tools
= new styles

AI as a "mainstreamification" process
Read more -> ChatGPT Is a Blurry JPEG of the Web

AI rise the standards of design
…and this is good, because more people participate, and the world is nicer. (designwise only)

"design" has always been about prompting

Mediocrity is automated
You'll need to do the hard 10% of the job.

Designer + AI
> Designer

Worldbuilding as a framework for designing spaces, objects and fashion
read more -> Worldbuilding
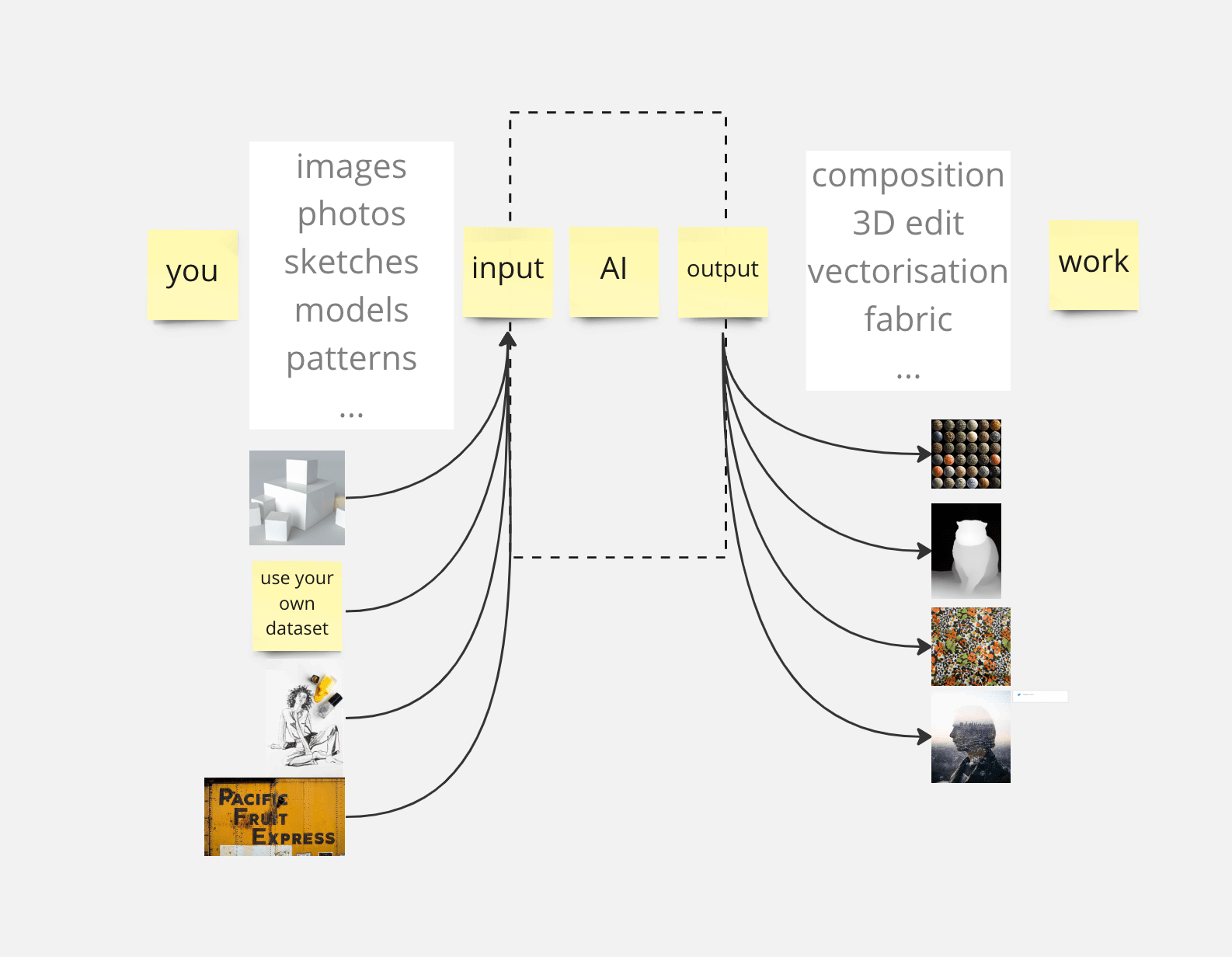
using AI with intent
hack the input/output of your AI systems
Tools:

We used a collaborative space to interact with text and image models
try it -> fermat ws
We also had 15 computers running stablediffusion locally using SD-web-ui , installed with several models and extensions.
And bunch of huggingface spaces setup with large GPUs to run fast and smooth experiments:

extracting depth from image

using physical mockups + photo to guide the image generation process
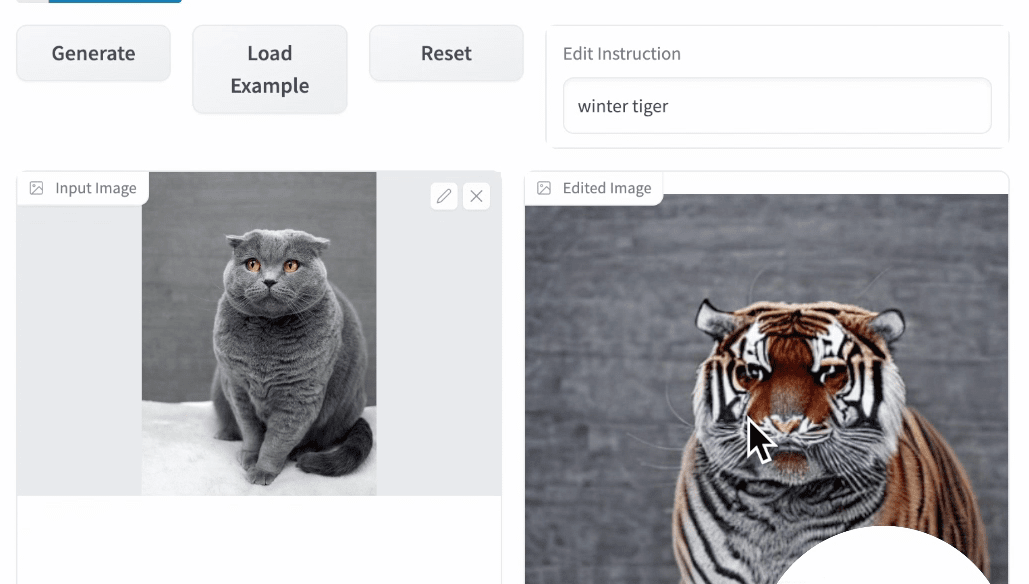
conversational image editting
We also explored workflow-specific tools as:
text to PBR material -> https://withpoly.com/
runway’s magic tools -> https://runwayml.com/ai-magic-tools/
sketch to render -> https://www.vizcom.ai/
AI 360 HDR panoramas -> https://www.latentlabs.art/
custom networks -> https://www.kaiber.ai/
NeRFs -> https://lumalabs.ai/
AI puppets -> https://www.d-id.com/
And reviewed guides and helpers:
prompt enhancer -> promptist https://huggingface.co/spaces/microsoft/Promptist
prompt explorer -> https://www.krea.ai/
art styles glossary -> https://gorgeous.adityashankar.xyz/
text2img archives -> https://lexica.art/
illustration archives -> https://vectorart.ai/
And also talked about what's coming:
AI Designers -> https://uizard.io/autodesigner/
AI UI/UX -> https://www.usegalileo.ai/
Text to Video -> https://research.runwayml.com/gen1
Text to 3D -> https://dreamfusion3d.github.io/
Body digitizers -> https://xiuyuliang.cn/econ/
Trainable AI Voice -> https://beta.elevenlabs.io/
Custom language models -> https://www.chatbase.co/
in short: AI is good, and you too
🙌
in short: AI is good, and you too 🙌
Glossary & Links
Awesome Generative AI -> https://github.com/steven2358/awesome-generative-ai
Machine Learning for Art -> https://ml4a.net/
AI + Design Usecases -> https://aidesigntools.softr.app/
Diffusion Bias explorer -> https://huggingface.co/spaces/society-ethics/DiffusionBiasExplorer
🙋 Continue the conversation in this thread .> https://twitter.com/cunicode/status/1631386323519938574